Making Computer Understand my WORDS
Deep learning for NLP

I am a self-taught learner from India :)
How to teach Words to our computer

A great man once said.
It's not easy or hard or easier or even hardier
You see we already know that we can teach an AI model to learn about pictures space satellite imaging
But what about Language?
Why leave that, when we can do image classifications
So let's create a
Sentimental Analysis Model.
Let's dive deep in.
Hi I'm Sriram your personal informative friend.
God, I wanted to say that sentence for a Long Time Now😂.
Let's go babyyy...

The Things We are going to Cover
- What is NLP and Why is NLP.
- Loading Data For NLP📃.
- Analysing the result of our model's🧐.
- Testing The Model🐱💻.
- Confusion Matrix📊.
LET"S START FROM THE BEGINNING

What is NLP and Why is NLP
What is NLP ?
NLP - Natural Language Processing.
The Word Describes itself isn't that amazing 😊.
Natural Language - which in this example English.
Processing - processes the words so that we can understand the Sentiment Behind them 😎 .
That's it Really there is nothing else You need to know about in this Sentence 😙.
Now that you know about this NLP fancy term let's go even deeper.
Why is NLP?
Well in simple terms: NLP models can remember and recall what the last word and its previous word are to predict what the next word is going to be.
In our case we are going to predict whether a person is.
'sad', 'angry', 'in love', 'in surprise', 'in fear', 'in joy' By just looking at their text or Comment.
If you ask is that all? For This Blog well Yes Actually(Foreshadowing).
But before jumping into a model we need data.
so let's cook them up.

Loading Data For NLP
Our favorite Dataset website kaggle(click me) contains all the food and ingredients
⚠ If You want to continue parallel with me then @click me to get the full code
🔺 I'm not going to cover my codes here but if you are interested you can visit the above link.
What type of format does our computer understand?.
That's a great question 🤔.
Well, the answer is 'Numbers'.
Yeah, you heard me right IN NUMBERS.
We need to change our Text into numbers.
How?

In the above examples:
hello = 1(yeah its supposed to be hello😅).my = 11.friend = 255.
It doesn't matter which number goes to which.
the thing that matter is if the computer sees the number 255 then we know that it's a "friend".
Now there is actually another fancy word for this as usual.
And that word is Drum roll, please.....
Tokenizer.
If you heard this term ever again in your life this is what it means :
Assigning Each Letter To A Number.
Wait but it's not over yet.
there is also another thing that we have to do.
The Embedding.
As I like to call it.
(the original word is just "embedding").
Now, what is this jargon?
well, the word Embed means.
fix (an object) firmly and deeply in a surrounding mass.
" he had an operation to remove a nail embedded in his chest".
Now we know that in simple terms 'Embed' means 'Attaching'.
Now, what is this had anything to do with our data ?
Our computers indeed needed only numbers to do computation but if that number is between zero and one(0 to 1) then it will be a lot faster and it's easy to understand by our computer.
Embedding is what going to help us in this situation.
It's going to take our Tokenized words(You already know what this is😎) and passing this into an Embedding layer gives us this.
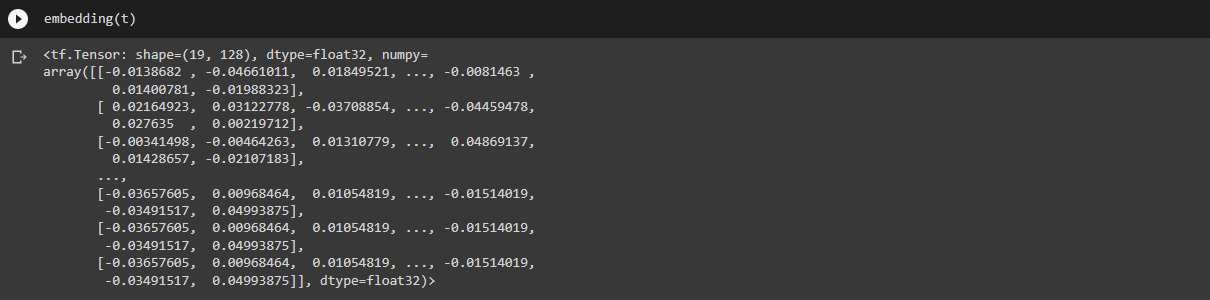
128 rows with 19 columns representing that "hellow my friend".
Now, what are these values? It's nothing actually it's more randomly generated values for our sentence.
But the catch is our model can learn this while training so it can change this into its understandable format (in numbers obviously).
More like Notes📝that we take while reading.
but this already has conditions like.
- The 'Words' need to be in 19-column representations.
- And It can Take up to 128 Words in a single sentence.
So we are attaching(embedding) that tokenizer into the matrix of (128,19) random values.
And that's it Now you are all caught up..
Now the model Creation Part:
(Which Again I'm not going to Cover in this Blog I'm planning to do it separately).
(It needs its own Blog).
(Interested people Can look into my codes)
But Now Let's Do the Judgemental Part of this Blog.
Analysing the result of our model's

After Created All the models That are Trained With our Data is then Made a Prediction.
We Compared That Prediction to its original Value.
If They are the same "The Accuracy Would be High".
predicted value: "Love" = original value: "Love".
If They are not the same "The Accuracy Would be Low".
predicted value: "Hate" = original value: "Love".
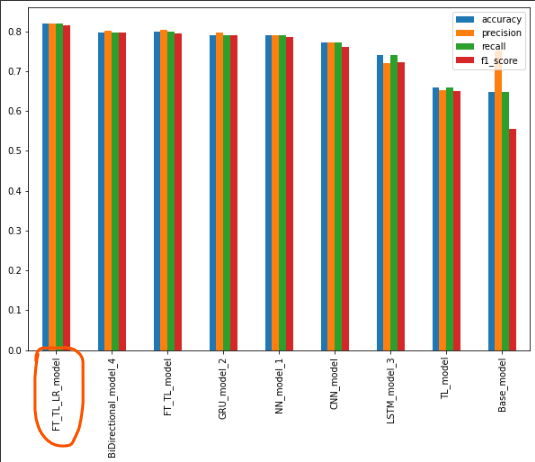
As You can see the FT_TL_LR_model performed better than any other model in that list.
It's Actually a Transfer Learning Model @if you don't know what I'm talking about Click Me☺it only takes 5 minutes of your wonderful time.
Let's Take that model And Make a Prediction on our Test Data @Click Me if you Don't Know What Test Data is.
Testing The Model
Let's Check it in our own words.
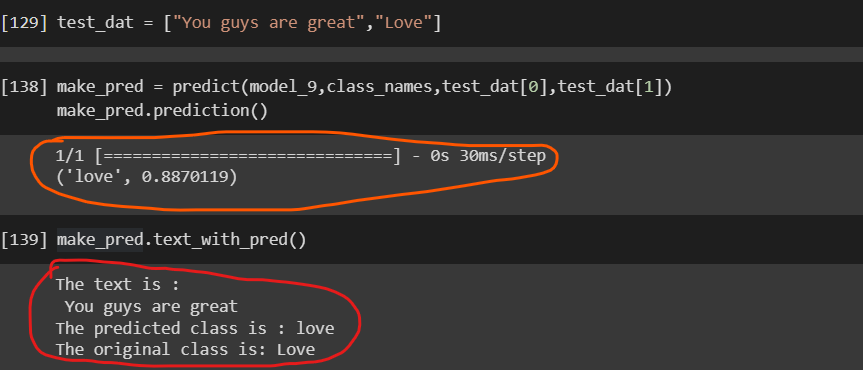
It's predicting the right feeling💌 and its 88% confidence in its prediction😎.
Confusion Matrix
Test Data look's like this without Any Tokenizer or Embedding.
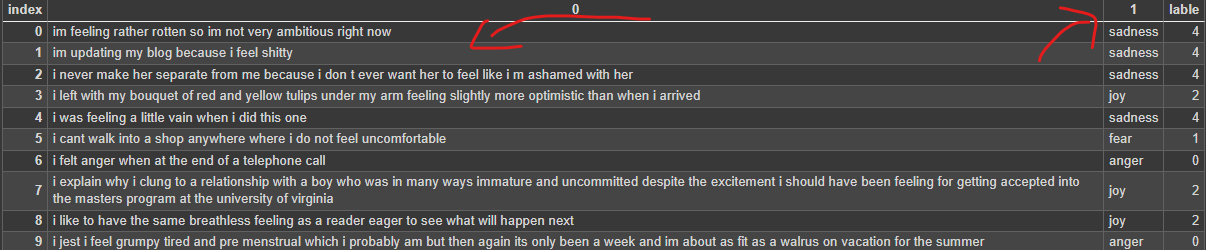
The Data has 2000 Sentences just like this.
Now Let's see how many values our Model got right in our test data.
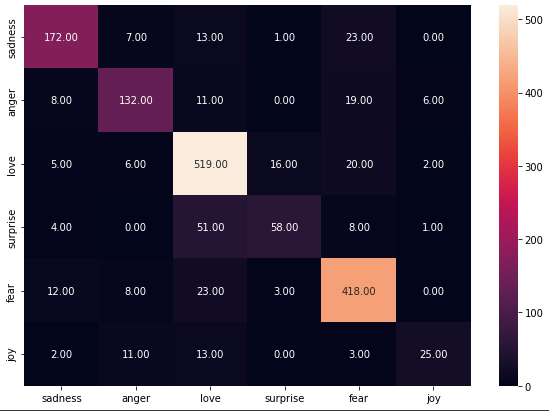
As you can see our Transfer Learning model Get Most things right.
don't know what this confusion matrix is then click me

And it got 82% accuracy on our Test Data Which is Great (8 out of 10 images are right).
Well That's it.

Now you actually know how our computer can learn Language🥳.
Thank-You For Your Amazing Time.
Bye ヽ(≧□≦)ノ.
Code : click me.
Linkedin : click me.



